In der Peptid-Bastelstunde
Juliet Merz
FRANKFURT: Durchhaltevermögen und ein wenig Glück haben schon vielen Wissenschaftlern geholfen, während ihrer Forschung auf die richtige Fährte zu stoßen. Manchmal reicht aber auch der scharfsinnige Blick eines Bioinformatikers, der beim Durchschauen der Sequenzdaten an der richtigen Stelle einen Geistesblitz hat.
In der Arbeitsgruppe Molekulare Biotechnologie von Helge Bode an der Goethe-Universität in Frankfurt am Main dreht sich alles um niedermolekulare Naturstoffe aus Bakterien und Pilzen. „Zum einen möchten wir herausfinden, welche Naturstoffe die erwähnten Mikroorganismen eigentlich herstellen und warum genau sie das tun. Zum anderen versuchen wir, die Herstellung der Naturstoffe nachzuahmen und zu variieren“, erklärt der Biologe und Chemiker. Dafür hat Bode gute Gründe, denn etliche dieser chemischen Verbindungen haben in der Vergangenheit ihr Können bereits unter Beweis gestellt. Die Naturstoffe, für die sich Bode und sein Team interessieren, sind vor allem nicht-ribosomale Peptide. Prominente Beispiele sind etwa die Antibiotika Penicillin oder Vancomycin, aber auch das Immunsuppressivum Ciclosporin.
Was all diese Peptide gemein haben: Sie werden über nicht-ribosomale Peptidsynthetasen (NRPS) hergestellt. Diese riesigen Proteine kommen hauptsächlich in Bakterien sowie Pilzen vor und gehören zu den größten zellulären Enzymen überhaupt. „Die bislang größte bakterielle NRPS mit dem Namen Kolossin-Synthetase aus Photorhabdus luminescens hat eine Masse von 1,8 Megadalton und ist damit größer als die große Untereinheit des Ribosoms in Bakterien“, verdeutlicht Bode die Dimension des wahrhaftig kolossalen Enzyms.
Da das Protein so gigantisch ist, nimmt die dazugehörige DNA-Sequenz im Genom natürlich recht viel Speicherplatz ein. 49.100 Nukleotide, um genau zu sein. Damit besetzt das Kolossin-Synthetase-Gen circa ein Prozent des gesamten Erbguts. Und es gibt Bakterien, die bis zu 15 unterschiedliche NRPSs mitschleppen. „Für Bakterien und Pilze müssen die Enzyme, beziehungsweise ihre Peptide, sehr wichtig sein, denn eine so große Gensequenz immer mit zu replizieren, ist ein enormer Energieaufwand“, schlussfolgert Bode.
Molekulare Giganten
Wie die gigantischen Enzyme aufgebaut sind und für was sie gut sind, ist schon seit mehr als zwanzig Jahren bekannt. „Ein NRPS ist in unterschiedliche Module eingeteilt. Das kann man sich vorstellen wie eine große Fabrik, die Module sind die einzelnen Abteilungen“, vereinfacht Bode das Prinzip. Jedes Modul trägt wiederum mindestens drei Domänen: Die Adenylierungs (A)-Domäne, die für die Aminosäureauswahl und -aktivierung zuständig ist, eine 4’-phosphopantetheinylierte Thiolierungs (T)-Domäne, welche die Aminosäuren trägt, und eine Kondensations (C)-Domäne, welche die Aminosäure mit der eines darauffolgenden Moduls verknüpft und die Peptidkette damit verlängert. Die Domänen-Reihenfolge in einem Modul ist C-A-T. Dazu können noch zusätzliche Domänen kommen, welche das Peptid weiter gestalten. Insgesamt sind die NRPSs wahre Modifikations-Künstler. So können sie auch Fettsäuren und nicht-proteinogene Aminosäuren einbauen, Ringstrukturen wie Thiazole oder Oxazole erzeugen oder die Peptidbindungen methylieren.
Für Biotechnologen sind die NRPSs ein willkommenes Werkzeug, um nicht-ribosomale Peptide zu verändern oder sogar ganz neu herzustellen. Das einzige Problem bisher: Wie bringt man eine NRPS dazu, genau das zu tun? Die Antwort lieferten Bode und seine Kollegen 2018 in einer Publikation in Nature Chemistry (10: 275-81).
Die Gruppe hatte eine Methode entwickelt, mit der Fragmente in der Synthetase einfach ausgetauscht werden können – das Exchange-Unit-Konzept. Dafür überlegten sich die Biotechnologen ein beliebiges Peptid und entwarfen die Gensequenz zur passenden NRPS. Den Zusammenbau der Sequenz übernahmen Hefe-Zellen, die mit DNA-Fragmenten der einzelnen Teil-Sequenzen der Exchange Units A-T-C „gefüttert“ wurden und dank homologer Bereiche diese Fragmente in der richtigen Reihenfolge verknüpften. Bode und sein Team mussten die Plasmide lediglich isolieren und in Escherichia coli einschleusen. Dort fand schließlich die finale Produktion der Peptide statt.
Und tatsächlich bekamen die Forscher NRPSs, die ihre gewünschten Peptide herstellten – aber nicht immer. „Das Problem ist, dass eine erfolgreiche Verknüpfung der Aminosäuren teilweise von den nachfolgenden Kondensations-Domänen abhängt“, erklärt Bode eine bisherige Schwachstelle des Systems. Denn nicht nur die A-Domäne ist auf eine Aminosäure spezialisiert, auch die C-Domäne kann manchmal nur bestimmte Aminosäuren miteinander verknüpfen. „Man vermutet, dass die C-Domäne eine Art Gate-Keeping-Funktion, also Kontrollfunktion hat, damit keine ‚falschen’ Peptide entstehen.“
Sture Domänen
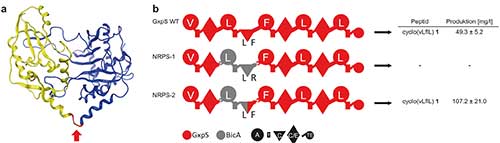
Bei der Wahl der C-Domäne mussten die Forscher also darauf achten, welche Aminosäure sie natürlicherweise als nächstes verknüpfen kann. Im Versuch wollten die Forscher ein Modul aus der bakteriellen NRPS BicA in eine andere NRPS einbauen – was jedoch zu ziemlichen Schwierigkeiten führte. Denn die C-Domäne von BicA, die auf die Aminosäure Leucin folgt, akzeptierte als nachfolgende Aminosäure stur nur Arginin. Zum Ärgernis der Forscher, die eigentlich ein Phenylalanin eingeplant hatten. Die gewünschte NRPS und das Peptid ließen sich so nicht synthetisieren. Diese Eigenheit der C-Domänen behinderte die Forscher im Design der Peptide natürlich massiv.
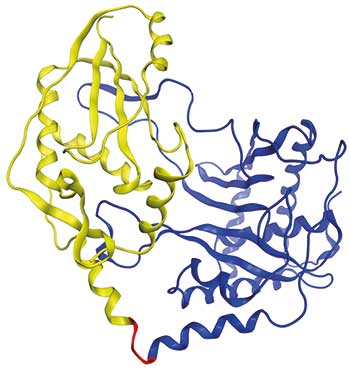
Der Geistesblitz des promovierenden Bioinformatikers Kenan Bozhüyük, der auch Co-Erstautor der daraus resultierenden Studie ist, brachte die Lösung (bioRxiv, doi: 10.1101/354670). „Als sich Kenan am Rechner die Sequenzen von unterschiedlichen C-Domänen anschaute, bemerkte er, dass sie sich an einer Stelle sehr ähnelten“, erinnert sich Bode. Die C-Domäne ist ein Pseudo-Dimer und sieht räumlich aus wie ein Herz. In der Mitte, quasi der Herzspalte trägt sie eine relativ konservierte Sequenz, wo auch die enzymatische Reaktion stattfindet. „Wir haben dann einfach probiert, die Domäne genau an dieser Stelle zu schneiden“, – womit die Biotechnologen Erfolg hatten.
Die zwei Herz-Hälften scheinen für je eine Aminosäure spezifisch zu sein. Für den erneuten NRPS-Zusammenbau in der Hefe schleusten die Biotechnologen also nicht wie zu Beginn einzelne Gensequenzen mit Exchange-Unit-Aufbau A-T-C ein, sondern verwendeten Fragmente, die mit einer halben C-Domäne begannen und mit der Hälfte der nachfolgenden C-Domäne endeten. „Wir trennten die Fragmente also immer in der Mitte der C-Domäne“ (siehe Abbildung oben).
Durch die konservierte Stelle in der Herzspalte ließen sich die C-Domänen-Hälften problemlos verknüpfen und die Reihenfolge der Aminosäuren beliebig kombinieren. „Wir hatten ziemliches Glück, muss man sagen. Auf die Idee, an dieser Stelle zu schneiden, ist vorher einfach noch niemand gekommen“, schmunzelt Bode. Kein Wunder, denn die C-Domäne bleibt weiterhin ein Rätsel. „Wie sie molekular im Detail funktioniert, weiß niemand so genau.“
Dank diesem Trick sind den Forschern kaum mehr Grenzen gesetzt. „Wir können so nicht nur selbst entworfene nicht-ribosomale Peptide produzieren, sondern auch ganze Peptid-Bibliotheken durch mehr oder weniger zufällig designte NRPSs erstellen.“ Und auch die Synthese von Antibiotika und anderen nicht-ribosomalen Peptiden könnte damit verbessert werden. Denn bisher entstehen mit den mikrobiologischen Verfahren nach wie vor ungewollte Derivate, die hinterher chemisch-analytisch abgetrennt werden müssen.
Glücklicherweise hat Bode erst kürzlich einen ERC Advanced Grant eingeworben. Die insgesamt 3,16 Millionen Euro Fördermittel möchten die Frankfurter Biotechnologen in den nächsten fünf Jahren nutzen, um das System noch besser zu verstehen. Ziel ist es, quasi am Reißbrett halb- oder sogar vollautomatisiert NRPSs zusammenzusetzen oder zu modifizieren, um so nicht-natürliche Peptide herzustellen.
Aber auch eine Peptid-Bibliothek steht bei Bode und Co. ganz oben auf der Prioritätenliste. „Im Endeffekt möchten wir die Peptid-Produktion mit einem funktionellen Screen koppeln, sodass wir aus der Bibliothek direkt die biologisch aktiven Substanzen selektieren können, beziehungsweise die Bakterien, welche die Peptide herstellen“, hofft Bode.
Zwei riesige Projekte, die sich das Team von der Goethe-Universität da vorgenommen hat. „Man wächst ja schließlich mit seinen Aufgaben“, bleibt Bode optimistisch und schmunzelt: „Wobei mir meine Körpergröße von zwei Metern eigentlich reicht.“
Letzte Änderungen: 10.10.2019