Nehmen wir als Beispiel ein fiktives Medikament zur Fiebersenkung. Angenommen, es gibt viele publizierte Studien, die alle die gleiche Effektgröße messen: Wenn ein Patient, sagen wir, 40°C Fieber hat, um wie viel °C sinkt im Schnitt die Temperatur eine Stunde nach Einnahme des Medikaments, im Vergleich zu einer Placebogruppe? (Wie gesagt, alles nur fiktiv und zur Veranschaulichung)
Auf die Symmetrie des Trichters kommt es an
Kleine Studien, die vielleicht nur ein Dutzend Teilnehmer haben, liefern wegen statistischer Schwankungen recht verschiedene Schätzungen für diesen Wert, z.B. alles mögliche von 0,5°C bis 2°C Fiebersenkung. Je mehr Teilnehmer eine Einzelstudie hat, desto weniger spielt der Zufall eine Rolle, und desto mehr werden sich die gemessenen Effektgrößen in verschiedenen Studien angleichen. Insgesamt aber sollten Studien, die den "wahren" Effekt überschätzen, nicht zahlreicher sein als solche, die ihn unterschätzen - denn der Zufall kennt keine bevorzugte Richtung.
Das bedeutet: Trägt man die Effektgröße jeder Studie auf der x-Achse und ein Maß für die Studiengröße (bzw. deren Präzision) auf der y-Achse auf, bekommt man eine Punktewolke in Form eines auf dem Kopf stehenden Trichters. Je größer die Studien, desto kleiner die Streuung, aber die Punkte sollten mehr oder weniger symmetrisch links und rechts der Mittellinie liegen. Wenn die Daten nicht trichterförmig streuen, sondern sich verdächtig zu einer Seite neigen, dann "fehlen" offenbar Punkte im Plot – z.B. Studien mit negativen Ergebnissen, die Forscher in ihren Schubladen verstecken.
Man muss allerdings auch ein wenig vorsichtig sein bei der Interpretation von Funnel-Plots. Denn eine Annahme ist ja, dass die einzelnen Studien, die im Plot auf je einen Datenpunkt eingedampft sind, tatsächlich vergleichbar sind, z.B. hinsichtlich ihrer Methodik und der untersuchten Population. Das ist in der Praxis selten der Fall, und die anschaulichen Trichter sind deshalb auch in die Kritik geraten (siehe z.B. hier). Für auffällig schiefe Punktewolken gibt es nämlich manchmal harmlosere Erklärungen als Publication Bias.
Schieflagen springen auch Nicht-Statistikern ins Auge
Aber dennoch sind Funnel Plots ein beliebtes Werkzeug, um Probleme in "Studien über Studien" (Metaanalysen) aufzuspüren – unter anderem wohl deshalb, weil Schieflagen auch Nicht-Statistikern förmlich ins Auge springen.
Eine wichtige Rolle spielt der Funnel-Plot zum Beispiel in einer viel zitierten Metaanalyse zur Wirksamkeit homöopathischer Heilmittel (Lancet 366: 726-32 (2005) ). Die Autoren um Shang et al. hatten darin mehr als 110 Studien zu Homöopathika ausgewertet. Und das aus diesen Daten gebastelte Funnel-Diagramm sieht ganz und gar nicht trichterförmig aus, es "fehlen" vor allem kleine Studien mit negativem Effekt:
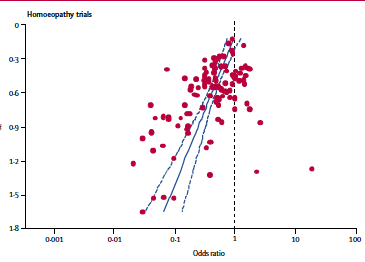
(Quelle: Shang et al. 2005, Fig.2 )
Der Funnel Plot von Shang et al. ist ein deutlicher Hinweis darauf, dass kleine, qualitativ fragwürdige Studien zu Homöopathika vor allem dann publiziert wurden, wenn das Ergebnis positiv ausfiel, im Sinne einer Wirksamkeit homöopathischer Mittel. Publication Bias also. Je besser und größer die Studie, desto mehr schwinden die Hinweise auf eine mögliche Wirksamkeit der Zuckerkügelchen, so könnte man die Schlussfolgerung zusammenfassen.
Kürzlich hat nun auch bei den Psychologen ein Trichter-Diagramm ein peinliches Ergebnis ausgespuckt, berichtet der Blogger mit dem Pseudonym "Neuroskeptik". Es geht dabei um das sogenannte Romantic Priming. Dieser Hypothese zufolge sind Menschen eher bereit, viel Geld z.B. für eine neue Uhr auszugeben, wenn sie zuvor in Stimmung versetzt wurden – mit einer Geschichte, die mit der Uhr überhaupt nichts zu tun hat, sondern von der Möglichkeit handelt, einen attraktiven Partner kennenzulernen. Gleich 15 Studien verschiedener Gruppen, mit insgesamt 43 Experimenten, scheinen die "Romantic Priming Hypothese" zu belegen. So viele Forscher können sich nicht irren, oder? Britische Forscher um David Shanks (University College London) versuchten, die Ergebnisse in 8 separaten Experimenten zu verifizieren, mit 1600 Probanden. Heraus kam – kein Beleg für die Romantic-Priming-Hypothese, die Ergebnisse all der früheren Studien ließen sich nicht reproduzieren. Hatten Shanks et al. bei ihrem Versuchsaufbau vielleicht einfach etwas falsch gemacht?
Wohl kaum, und auch hier ist ein Funnel Plot der rauchende Colt:
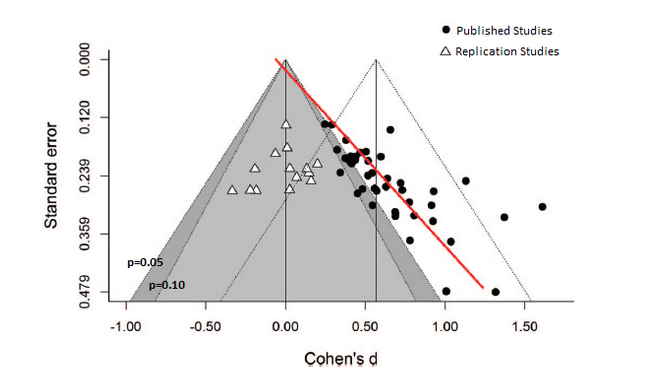 (Quelle: Shanks et al 2015)
(Quelle: Shanks et al 2015)
Wieso sieht man im Plot eine imaginäre Linie?
Die Datenpunkte der Original-Studien versammeln sich auf einer Seite des Trichters; und wie bei den Homöopathen-Studien wird der gemessene Effekt umso kleiner, je größer (und präziser) die Studie ist. Aber nicht nur das stört Neuroskeptic: Er weist darauf hin, dass die Punktewolke ausgerechnet die Bereiche des Plots regelrecht umarmt, in denen die Grenze zwischen statistisch signifikanten (p < 0,05) und nicht-signifikanten (p > 0,05) Daten liegt. Der magische p-Wert von 0,05 als Ergebnis eines statistischen Tests entscheidet in den Augen vieler Reviewer und Journal-Editoren darüber, ob eine Hypothese als hinreichend belegt gelten kann, oder zumindest als publikations-würdig. Er ist ist aber eine völlig willkürlich gezogene Grenze. Anders gesagt: Wenn Studienergebnisse ehrlich und vollständig berichtet werden, sollte diese Linie im Funnel Plot überhaupt keine Rolle spielen.
Das könnte nun bedeuten: Die Psychologen-Community hat die Ergebnisse ihrer "Romantic-Priming"-Studien selektiv berichtet und negative Ergebnisse unter den Tisch fallen lassen – und das ist noch die nettere Interpretation.
Ob es für die Schieflage des Romantic-Priming-Trichters auch eine harmlosere Erklärung gibt als Publication Bias und/oder p-Hacking? Neuroskeptic zumindest glaubt nicht daran: "Der Funnel Plot legt nahe, dass Romantic Priming nicht existiert, und dass die vielen Studien, die diesen Effekt berichtet hatten, falsch liegen".
Hans Zauner
Illustration(Symbolbild) © 19510808ivanov / Fotolia
Letzte Änderungen: 06.01.2016







